A Recognita mint technológia és mint üzlet
Hosszú ideje foglalkoztatja és még sokáig foglalkoztatja majd a kutatókat, megoldásfejlesztõket a Pattern Recognition vagyis az alakfelismerés, mintaazonosítás problematikája. Jelen esetben tekintsünk el a háromdimenziós elrendezésektõl és maradjunk a kétdimenziós objektumok területén, azon belül is egy speciális, de napjainkban már igen széles körben elterjedt és használt technológia és megoldás, az optikai karakterfelismerésnél. A látó élõlények a szem által közvetített képet használják alakfelismerésre. A számítástechnika is ezt a sémát követi, amikor valamely képfelvevõ eszköz elõállította kép tartalmát igyekszik felderíteni, azonosítani. Tudjuk, hogy a gépi mozgókép állóképek sorozata, így nyugodtan szorítkozhatunk az állóképek vizsgálatára, különös tekintettel az optikai karakterfelismerésre, amely betûk, számok, jelek összefoglalóan karakterek , illetve az ezek által alkotott szövegek felismerésére irányul.
Mivel számítógépes megoldásról van szó, a számítógép pedig számokkal dolgozik, olyan képalkotó, illetve képbeviteli eszközre van szükségünk, amely digitális képet ad. Ilyen eszközök a digitális szkennerek vagy lapolvasók és a digitális kamerák. Jó tizenöt évvel ezelõtt, amikor az akkori idõk egyik vezetõ intézménye, a Számítástechnikai Kutatóintézet és Innovációs Központ (SZKI) matematikai, valamint elméleti laboratóriumaiban megkezdõdtek a mesterséges-intelligencia kutatások, különbözõ képfeldolgozási eljárásokat is kidolgoztak. Szükségessé vált ugyanis az egyre nagyobb számban érkezõ mûholdképek képi elemzése. Itt elõször katonai célú feladatok voltak, késõbb azonban már szerepet kaphatott olyan polgári alkalmazás is, mint egy nagy kiterjedésû gabonatábla mûholdképébõl megállapítani az esetleges betegségeket, rovarkárokat. Hamarosan megkezdõdtek a kísérletek analóg kamerák digitalizált képének feldolgozására is. Tekintettel azonban a nyolcvanas évek közepén beszerezhetõ kamerák és képdigitalizálók mûszaki színvonalára, a generált képek felbontása, részletgazdagsága vagy mondhatjuk inkább, részletszegénysége miatt csak viszonylag egyszerû feladatokat lehetett megoldani, például, hogy megkülönböztessünk egy kört egy függõleges vonaltól.
Igazán komoly lehetõséget a lapszkennerek megjelenése
adott. A személyi számítógépek dinamikus
fejlõdésével és elterjedésével
a nyolcvanas évek végére létrejött számítástechnikai
környezet (300 dpi [pont/hüvelyk] felbontású szkennerek,
16 bites személyi számítógépek) megfelelõ
alapot adott a már jól használható karakterfelismerõ
technológia létrehozásához. A különbözõ
alakfelismerõ feladatok megoldásának az SZKI-ban logikus
folytatása volt a karakterfelismerés mint problémakör
kutatása, piacképes technológia és arra épített
termék kidolgozása, folyamatos továbbfejlesztése.
Ismerkedjünk meg néhány, az iparágban használatos fogalommal
A karakterfelismerést általában az OCR betûszóval jelölik (az angol Optical Character Recognition rövidítése). Ezt használhatjuk általánosságban is, de leginkább a géppel nyomtatott, írógéppel írt szövegek felismerését értjük alatta.
Az OMR Optical Mark Recognition speciális jelek, jelölõnégyzetek tartalmának felismerését szolgáló technológia neve.
Az ICR Intelligent Character Recognition pedig a kézzel írt nyomtatott nagy- és kisbetûk felismerési technológiája.
Miután egy, a képfeldolgozásban jobban elmélyült egyetemi hallgató néhány havi munkával képes (mondjuk, diplomamunkaként) mûködõ OCR-prototípust létrehozni és az így készült programok egész jó teljesítményt tudnak nyújtani valamely, elõre definiált karakterkészletben, joggal hihetnénk, hogy a használható OCR létrehozása nem túl nagy feladat. A gyors kezdeti siker után azonban évek kemény munkája következik, ha a való élet dokumentumainak széles skáláját figyelembe véve akarunk jól használható megoldást készíteni.
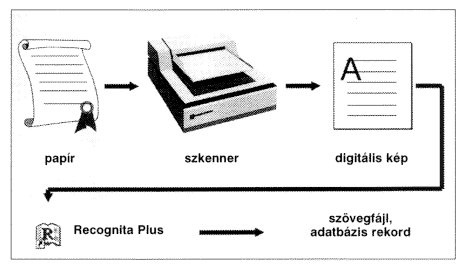
1. ábra. Az OCR (Optical Character Recognition) technológia
Mirõl is van itt szó? Szkenneljünk be (olvassunk be), mondjuk, egy A4-es szövegoldalt, melyen a szövegen kívül természetesen lehet kép, grafika stb. (1. ábra). Számítógépünkön megjelenik az oldal digitális képe (image). Sokan nem ismerve a lényeget, úgy gondolják, hogy a dolog ezzel rendben is van, és csodálkoznak, amikor a képen szereplõ szöveget nem tudják azonnal szövegszerkesztõjükkel feldolgozni. Nem is, hiszen ami e pillanatban ott van, az képpontok halmaza (egy karakternek kb. 2530 x 4050 képpont, pixel felel meg), mely halmaz alkotta kép lehet fekete-fehér, szürke skálás vagy színes. Ha a kép fekete-fehér, egy pont jellemzésére elegendõ 1 bit, ha szürke skálás, kell hozzá 1 byte (8 bit), ha színes, akkor pedig 3 byte a vörös-zöld-kék (RGB) színek meghatározásához. Mielõtt a karaktert felismerné, egy sor lépést kell megtennünk, amit összefoglalóan kép-elõfeldolgozásnak nevezünk. Ahhoz, hogy az OCR-felismerõ algoritmus (vagy még inkább algoritmusok gyûjteménye) jó munkát végezzen, megfelelõen pozicionált, csak a felismerendõ szöveget tartalmazó tiszta képrészeket kell kapnia. Lehet, hogy a lapot véletlenül fejjel lefelé tettük be a lapolvasóba. Ezt egy speciális, a szövegsorokat alkotó képfoltokat elemzõ program felismeri, és a képet 180 fokkal elforgatja (rotáció). Amíg ez az automatizmus nem volt, a portré-tájkép-választást is kézzel kellett megoldani. Ugyancsak elõfordulhat, hogy a lap nem pontosan pozicionálva kerül az olvasóba, ilyenkor úgynevezett ferdeségkorrekcióra (deskew) van szükség. Mindkét eset különösen gyakori lehet a vak felhasználóknál, akik számára az OCR az egyetlen lehetõség ahhoz, hogy mindennapi nyomtatott (nem Braille) dokumentumokat külsõ segítség nélkül olvashassanak.
A most már megfelelõen pozicionált képrõl ezután el kell távolítani az oda nem illõ, például szennyezõdések okozta foltokat, pöttyöket. E feladat különösen kritikus, ha arra gondolunk, hogy az ékezeteket, jeleket kifejezetten káros lenne eltávolítandó objektumoknak tekinteni.
A következõ lépés az egyes képrészek, vagyis a lapszerkezet azonosítása. Meg kell határozni, mi szöveg és mi nem szöveg (kép, fotó, grafika). Következik annak meghatározása, hogy a felismerõmotor (OCR engine) milyen sorrendben fogja az egyes szövegrészeket, mondjuk, egy szövegszerkesztõnek átadni (gondoljunk itt például a többhasábos lapszerkezetre).
A lapszerkezetelemzése során meg kell találni az OCR-szempontból érdekes részeket. A szöveges dokumentumok egy- vagy többhasábosak, egy hasábon belül a szöveg bekezdésekre (paragrafusokra) tagolódik. A paragrafus jellemzõje lehet, hogy elsõ sora esetleg beljebb kezdõdik, az utolsó sora pedig nem ér ki a sor végéig. A hasábok meghatározására viszont az õket elválasztó fehér terület szolgál. Két hasáb között általában néhány karakter szélességû fehér függõleges csík van, a program ezt a területet viszonyítja a mellette található sokkal szélesebb, fekete-fehér képpontokat tartalmazó területhez. A hasábos lapszerkezet felismerése nagyon fontos, mert egy felismert szöveget nem lehet úgy továbbadni, hogy például az elsõ hasáb elsõ sorát néhány szóköz után követi a második hasáb elsõ sora. A hasábokat a felismerés után az olvasási sorrendnek megfelelõen kell egymás után illeszteni.
A hasábokhoz hasonlóan oszlopokat tartalmaznak a táblázatok is, ezek olvasási sorrendje azonban más. A táblázatokat a függõleges oszlopok ellenére vízszintesen kell olvasni, szigorúan megtartva az egymás alatt elhelyezkedõ karakterek pontos pozícióját. Itt az egyes szövegrészek igazítása segíthet: a hasábok általában egyidejûleg jobbra-balra, a táblázat oszlopai pedig csak balra, középre vagy csak jobbra igazítottak.
A szigorú tördelésû dokumentumoknál, például a verseknél minden sor külön paragrafusként kezelendõ, így az automatikus szerkezetfelismerésre elég kicsi az esély; tehát a programnak lehetõséget kell adnia a kézi beavatkozásra.
A felismerés során nem csak a karakter kódjára
vonatkozó információkat kapjuk meg, sokat megtudunk
a karakter attribútumáról (dõlt, aláhúzott,
kövér, betûméret stb.) is, sõt a pontos
elhelyezkedésérõl a lapon. Ezek az adatok a kódokkal
együtt átadhatók egy intelligens szövegszerkesztõnek,
így a lap teljes formátuma tovább él, azaz
minden a helyén van, csak éppen a szöveges képrészek
már szövegként szerepelnek.
A karakterfelismerés néhány buktatója
Az OCR-folyamat elsõ lépése a szegmentálás,
amely nem más, mint az egyes karaktereket alkotó képpontok
csoportosítása, összerendelése. Elsõ ránézésre
a feladat egyszerûnek tûnik, vagyis az egymással közvetlen
kapcsolatban lévõ képpontok alkotnak egy karaktert.
De gondoljunk a több különálló rész
alkotta elemekre, mint a kettõspont vagy a felkiáltójel,
nem beszélve az ékezetes karakterekrõl. A gondot csak
fokozza, ha a beszkennelt kép túl világos. A karakterek
vonala ilyenkor elvékonyodik és a karakterek széttöredeznek
(2. ábra). Ellenkezõ esetben, ha a kép
sötét vagy kövér, fonttal állunk szemben,
az egyes karakterek összeérhetnek (3.
ábra). A legrosszabb a kettõ kombinációja.
A 4. ábrán látható
képet olvashatjuk 3000-nek vagy akár 3(XX)-nek is.
 |
 |
| 2. ábra. Több részre tört karakterek | 3. ábra. Egymáshoz érõ karakterek |
A következõ lépés a feature extraction(jellemzõk
kigyûjtése): numerikus értékek sorozatát
(tulajdonságvektor)
rendeljük a karakter alakjához. A legegyszerûbb eset,
amikor egyesek és nullák kétdimenziós elrendezésével
képezzük le a karakter képpontok geometriai elhelyezkedését.
Ez, amit kezdetben az OCR pionírok is használtak, a matrix
matching(mintaillesztés)
algoritmus. Noha egyes esetekben ma
is nagyon hasznos lehet ez a megközelítés, a ma használt
algoritmusok méret- és fontfüggetlen tulajdonságokat
kezelnek: például a görbületek, hurkok száma,
jellemzõ pontok helyzete, valamint más topológiai
és statisztikai jellemzõk. Az ideális
tulajdonságvektornak
két, egymással konfliktushelyzetben álló követelményt
kell teljesítenie. Tudnia kell megkülönböztetni egymástól
a hasonló alakú karaktereket (például 5 és
S, C és G), miközben rugalmasan kell tudnia kezelni az azonos
karakterek különbözõ variációit (például
különbözõ fontoknál). Végül is
ezeket a követelményeket nem lehet mindig maradéktalanul
teljesíteni. Vannak karakterek, amelyek csak néhány
képpontban különböznek egymástól (mint
a t, az f, lásd az 5. ábrán).
Az ilyenfajta eseteknél karakterspecifikus szabályokat kell
alkalmazni. A szegmentálási problémák, valamint
a hasonlóságokból adódó gondok a tipikus
forrásai az OCR-hibáknak.
 |
 |
| 4. ábra. Tört és egymáshoz érõ
karak-
terek kombinációja, ez a legrosszabb |
5. ábra. Karakterek néhány pixel
különbséggel |
Varázsszerek
Annak érdekében, hogy csökkentsük a széttöredezett, illetve egymással összeérõ karakterek okozta gondot, beavatkozhatunk már az elején a képalkotási folyamatba, meghatározva, hogy egy szürke skálás képen hol legyen az a vágási szint, amely végül is eldönti, hogy egy szürke képpontot a továbbiakban fehérnek vagy feketének fogunk-e tekinteni, vagyis alkotó eleme lesz-e egy karakternek vagy sem. A vágási szintet állíthatjuk manuálisan (vakok számára azonban ez nem lehet megoldás), de sokkal jobb eredményt érhetünk el azzal a kifinomult technikával, amely figyelembe véve az egyes képrészletek különbözõ megvilágítását, egyetlen oldalon belül is képes más-más vágási szinteket meghatározni a legjobb eredmény elérése érdekében. Ez a kifinomult technika sem segít azonban olyan esetekben, ahol már az eredeti dokumentumon például festék van egy helyen, amikor keskeny hézagnak kellene lennie. A többszörösen másolt dokumentumokon vagy faxokon található leggyakrabban ilyen folt.
Azzal, hogy egy szürkeskálás képbõl bizonyos megfontolásokkal fekete-fehér képet csinálunk, egy csomó, a képben lévõ információt eldobunk. A kínai Tsinghua Egyetemen kísérleteket végeznek a vágás nélküli feldolgozásra, amikor is közvetlenül a szürkeskálás kép alapján lehet meghatározni a karakterek legvalószínûbb alakját.
Noha egyfolytában karakterfelismerésrõl beszélünk, a speciális alkalmazási területeket leszámítva (például kevés adatot tartalmazó formanyomtatványok) valójában szöveget akarunk felismerni, így komoly segítségünkre lehetnek a nyelvspecifikus információk. Esetünkben azonban a lingvisztikai segítség kétélû fegyver, nem megfelelõ alkalmazása félreviheti a felismerést. Az egyes OCR-megoldások, nem tudván a hagyományos képfeldolgozó eszközökkel tovább növelni a felismerés pontosságát, kivétel nélkül szótárak és spell-checking (helyesírás-ellenõrzõ) modulok támogatását veszik igénybe a felismerési folyamatban. A legkevesebb, hogy a helyesírás-ellenõrzõ rámutat a nem megfelelõ szavakra, azonban az OCR-szoftverek ennél tovább mennek, a fel nem ismert karaktereket a legvalószínûbb megoldást jelentõ szóval helyettesítik. Lehetnek viszont szép számmal szavak, amelyeket a szótárak, illetve helyesírás-ellenõrzõk nem tartalmaznak, és persze elég nehéz azt automatikusan eldönteni, hogy vajon ezek korrekcióra szorulnak-e. Az angolban például sok rövid, számos betûvariációban létezõ szó van, így itt egy-egy rosszul felismert karakter könnyen túlélheti a nyelvi korrekciót. A másik probléma, hogy az OCR-hibák tipikusan csoportokban jelentkeznek, gyakorta a szó betûszáma is más, mint az eredetiben, így különösen nehéz automatikus becsléseket tenni. Tekintettel az ilyen típusú gondokra, csak az vezethet megfelelõ eredményre, amikor szoros kapcsolat van a szó képe és a nyelvi információ között.
Noha az OCR-programok mind pontossabbak, el kell fogadnunk, hogy akadnak hibák. Attól függõen, hogy az egyes algoritmusokat hogyan írták meg, más-más OCR-ek más-más típusú hibákat vétenek és azokat következetesen. Erre alapozható az a technika, amely segít a felhasználónak a hibák gyors kijavításában. Amint a felhasználó kijavított egy hibát a dokumentum elején, a program végigmegy az egész dokumentumon, és automatikusan kijavítja az azonos típusú hibákat. Itt a tanuló- és a javítófunkció dolgozik. Ezzel végül is eljutottunk oda, hogy bár egy OCR-program legfontosabb jellemzõje a felismerési pontosság, hasonlóan lényeges lehet a használat hatékonysága, amely a szkenneléstõl a kész dokumentumig terjedõ idõt jelenti, magában foglalva értelemszerûen a szkennelésen, felismerésen kívül a javításra fordított idõt.
Napjainkra az OCR meglehetõsen kiforrott technológia lett,
s könnyen hozzáférhetõ mindenki számára.
A szkenner mindennapi eszközzé vált, és ma már
a legolcsóbb szkennerhez is adnak valamilyen OCR-t, amely a legegyszerûbb
igényeket
képes is kielégíteni.
A Recognita OCR-technológiája egyike a világ legjobbjainak egyedülálló abban a tekintetben, hogy a világon a legtöbb nyelv karakterkészletét képes felismerni. Ez a 114-féle nyelv az összes latin, görög és cirill betûs nyelvet jelenti. Ha figyelembe vesszük, hogy mindinkább elektronizálódó világunkban milyen fontos, hogy a korábban csak papíron meglévõ szövegek elektronikus formában tárolódjanak, beláthatjuk az ilyen technológia kulturális jelentõségét. Különösen a kis nyelvek esetében ahol a korlátozott piaci méret üzletileg nem teszi megalapozottá saját technológia kifejlesztését tölthet be a nemzetközi, soknyelvû OCR kulturális missziót is. Mivel a nyelv a nemzeti kultúra alapja, igen fontos, hogy az irodalom, publicisztika, de nemkülönben a tankönyvek, az oktatási segédanyagok elektronikusan terjeszthetõ, visszakereshetõ formába kerüljenek, és akkor nem beszéltünk még a vak, látássérült, diszlexiás emberekrõl, akik e technika nélkül elzártak a nyomtatott információ elõl.
A Recognita helyzeti elõnyét azzal szerezte, hogy már
induláskor a soknyelvû Európában gondolkodott
és az OCR-programban a belsõ karakterábrázolást
két byte-ban valósította meg (egy byte a karakter
testnek, egy másik az ékezetnek) garantálva a karakterek
elegendõ mennyiségét, míg az elsõsorban
amerikai versenytársak lényegében csak az amerikai
piacot, így az angolt, valamint a nagy nyugat-európai nyelveket
tekintették irányadónak, és megelégedtek
1 byte-tal, s e korlátozás miatt késõbb sem
lehetett elmozdulni a sok nyelv irányába.
A Recognita mint üzlet
A Recognita mint üzleti vállalkozás létrehozásában hárman játszottak fõszerepet: Kovács Emõke és Marosi István fejlesztõi munkájának eredményeként jött létre az a technológia és a ráépülõ termék, amelyre alapozva az üzleti vállalkozás beindulhatott, TállaiBenedek marketing-szakértelme pedig életre hívta magát a vállalatot, és útjára indította a szakmai eredmények mellett a Recognitát mint sikeres üzleti vállalkozást.
A nagy politikai, gazdasági változások hajnalán, 1989-ben alapította a Recognita részvénytársaságot az SZKI tulajdonosként, úgy, hogy egy angol üzletembert társtulajdonosként is bevont. Utóbbira azért volt szükség, mert az akkori kormányzat ötévi társaságiadó-mentességgel és további öt évre nagymértékû adókedvezménnyel jutalmazta azokat a frissen alapított vállalatokat, amelyekben a meghatározott mértékû tõkenagyság mellett a külföldi tulajdonosi részvétel adott mértéket elért. A kedvezményhez kellett még, hogy a vállalat stratégiai fontosságú területen mûködjön, a szoftverfejlesztés, -gyártás pedig stratégiainak minõsült. A Recognita filozófiájához tartozott, hogy a két fõrészvényes mellett a vezetés és az alkalmazottak is birtokoljanak részvényeket. A Recognitát tehát a megfelelõ feltételekkel alapították, így mivel mûködésének az elsõ öt évében folyamatosan számottevõ nyereségre tett szert, a kormányzat által adott adómentességet kitûnõen ki tudta használni.
Az üzletet viszonylag akadálytalanul beindították, ugyanis abban az idõben a piac meglehetõsen üres volt, különösen Európában nem volt erõs konkurencia. Így a szerény tõkeellátottságú vállalat kevés marketingdollárja is elegendõ volt ahhoz, hogy két-három éven belül kiterjedt láthatóságot, vagyis piaci ismertséget érjen el a Recognita márkanév számára. A cég- és a márkanév azonossága pedig segített abban, hogy egyidejûleg az elõbbi is ismertté váljon. Mivel a technológia a maga soknyelvûségével eleve feltételezte a nemzetközi piaci jelenlétet, a cég fõ terméke a RecognitaPlus a kezdetektõl fõleg exportra készült, ami többek között abban nyilvánult meg, hogy elõször a termék angol nyelvû változata készült el, majd a piaci kapacitás függvényében a német változat, és csak azután jöhetett a magyar. A leghatékonyabb marketingeszköznek a külföldi szakfolyóiratokban megjelenõ méltató cikkek, a konkurensekkel való összehasonlító elemzések bizonyultak. Ezen kívül a vállalat marketing erõforrásait elsõsorban a szakkiállítási részvételre koncentrálta: a két legfontosabb az egyre nagyobb szerepet játszó hannoveri CeBIT és a Las Vegas-i Comdex volt.
A cégalapítást követõ két évben 1990-ben és 1991-ben a Recognita két leányvállalatot alapított fõ piacain, Németországban és az Egyesült Államokban. A német vállalatot éppen az egyesítés elõtt jegyezték be Lipcsében, így még nagyon gazdaságosan (NDK-s költségszinten) lehetett létrehozni. Az amerikai vállalat székhelyéül a Recognita a Szilícium-völgyet választotta, azon belül Sunnyvale városát. A német vállalat célja a piaci jelenlét erõsítése volt Európa legnagyobb felvevõpiacán, szervezve a marketingakciókat, a sajtókapcsolatokat, a termékelosztást, és megadva az eladás elõtti és utáni szolgáltatásokat a vevõknek. Az amerikai vállalat feladata viszont elsõsorban az átfogó partnerkapcsolatok kiépítése volt, továbbá az, hogy a szilícium-völgybeli személyes kapcsolatok ápolásával elsõ kézbõl gyûjtsék össze az információt, amit ha jól csinálnak, komoly gazdasági elõnyöket eredményezhet. Mindemellett az volt a nem titkolt szándék, hogy a leányvállalat értékelhetõ (3% fölötti) piaci részesedést szerezzen Amerikában.
A kilencvenes évek elején a Recognita volt az egyetlen önálló magyar kiállító a CeBIT-en, és sokáig az egyetlen magyar kiállító a legrangosabb amerikai informatikai vásáron, a Comdexen. Ezzel a cég egyfajta küldetést is teljesített, mert a szakmai közvélemény a Recognita jelenlétét magyar jelenlétként is értékelte.
1994 fordulópont volt a Recognita életében, ugyanis mind a külsõ, mind a belsõ feltételek jócskán megváltoztak. Ekkorra az amerikai leányvállalat globális aktivitásának eredményeként a vállalat számos stratégiai fontosságú partnerszerzõdést kötött amerikai és távol-keleti szkennergyártókkal, akik lényegében az európai piacot is lefedték (Hewlett Packard, Canon, Microtek, Mustek, Kye Genius stb.). Ezek a szerzõdések az úgynevezett OEM + upgrade üzleti modell alapjai. E modell szerint a Recognita rendkívül alacsony darabár mellett licencjogot ad az eredeti szkennergyártónak, az OEM-nek (Original Equipment Manufacturer). A szkennergyártó e licencjog alapján minden készülék mellé letesz egy Recognita OEM-verziót (Recognita Select, Recognita Standard), mely a csúcsmodell Recognita Plus csökkentett funkciókészletû változata. Amikor tehát a végfelhasználó megveszi a szkennert, talál benne végeredményben egy használható megoldást adó Recognita-programot, felismerési pontossága megközelíti a csúcsmodell ebbéli képességét, de egy sor kényelmi funkció, a használatot segítõ tulajdonság hiányzik belõle. A termék egyrészt használat közben rendszeresen felszólítja a felhasználót, hogy regisztráljon, azaz juttassa el adatait a Recognita vállalatnak, másrészt felhívja a figyelmet arra, hogy ezen OEM-változattal a termék birtokosa jogosult a csúcstermékre fellépni, upgrade-elni (frissíteni). Ez azt jelenti, hogy a teljes árnál lényegesen kedvezõbb áron juthat a legtöbbet tudó változathoz. Ez az OEM + upgrade modell robbanásszerûen kezdett elterjedni 1994-ben. A nagy amerikai versenytársak (Caere, Xerox) mind erõteljesebben aktivizálódtak Amerikán kívül is. Hatalmas harc kezdõdött a szkennergyártókért, a harcban a Recognita egyre-másra alulmaradt. Már csak elvétve sikerült az egész világra szóló szerzõdést kötni, de abból is kimaradt Amerika mint terjesztési terület. A szerzõdések hatálya földrajzilag azokra a területekre szûkült (kelet-európai, görög, török, valamint kisebb nyugati nyelvek), ahol a Recognita monopolhelyzetben volt. Azt, hogy a nagy versenytársak a Recognitával szemben terjeszkedni tudtak az OEM-partnereknél, nem technológiai, hanem marketingfölényüknek köszönhették.
Ezzel párhuzamosan megkezdõdött a piaci szereplõk átrendezõdése. Az egyik legjobb technológiájú amerikai Expervision például rossz marketingdöntésekkel egyszerûen padlóra küldte magát. A Caere egy jól irányított fúzióval eltüntette az OEM-üzletben számára veszélyessé váló, szintén amerikai Calerát. Oroszországban a semmibõl jött elõ és gyors növekedésnek indult a jól átgondolt, sikeres technológiai megoldásokat gyártó Bit (jelenleg Abbyy). A Recognita legfontosabb piaci területére, Nyugat-Európába egyre nagyobb tömegben lovagoltak be a szkennerek hátán a versenytársak: a Caere terméke, az OmniPage, és a Xeroxé, a TextBridge. Az élezõdõ konkurenciaharc erõsítette a Recognita vállalaton belüli problémáit, és kikényszerített egy sor, a jövõt szem elõtt tartó döntést.
Idõközben a tulajdonosi összetétel is megváltozott.
1993-ban az angol tulajdonos halálát követõen
üzletrészét egy amerikai kockázatitõke-társaság,
a Magyar
Amerikai Vállalkozási Alap (MAVA) mint pénzügyi
befektetõ vette át. Ekkor a tulajdonosi megoszlás
a következõ volt: SZKI 50 százalék, MAVA 30 százalék,
alkalmazottak 20 százalék. A kockázati tõke
természetrajzáról annyit érdemes tudni, hogy
általában érzelemmentes, még kisebbségi
jelenléte is erõteljesen hat az adott vállalatban,
katalizálja a vállalat fejlõdését, és
arra készül, hogy elõbb-utóbb nagy haszonnal
túladjon befektetésén. 1994-ben, amikor az SZKI vagyonát
az ÁVÜ privatizálta, a MAVA kedvezõ áron
meg tudta szerezni az SZKI 50 százalékos részesedését,
és ezzel tulajdonosi hányadát 80 százalékra
tornázta fel.
1995 és 1996 meglehetõsen ellentmondásos évek voltak a vállalat életében. Egyrészt a pénzügyi mérleget tekintve a vállalat katasztrofális helyzetbe került, ugyanis e két év alatt kemény veszteségek mellett teljes vagyonát elvesztette, másrészt a vezetés minden stratégiai elképzelése bejött. Rendkívül intenzív technológiafejlesztés eredményeként 1995 végére a Nevada Las Vegas Egyetem felmérésének eredményeként a Recognita a Xerox-szal együtt az elsõ helyen végzett a világ OCR-technológiáinak versenyében. Egy, az amerikai védelmi minisztérium által pénzelt kutatócsoport a Las Vegas-i egyetemen évrõl évre nagyon alapos összehasonlító elemzésnek vetette alá a világ OCR-termését. Ezzel a teszttel a Recognitának szerencséje volt, mert így egy független fórum nagyon alapos, több hónapos, sokféle és több millió karakteren alapuló teszt eredményeként meglehetõsen megbízható rangsort tudott felállítani a termékek között. Persze keserves volt látni, mondjuk az ötödik helyezést, és innen meggyõzni egy OEM-partnert, hogy velünk kössenek szerzõdést és ne a jobbakkal, de ezek a részletes elemzések a hibákat is pontosan megmutatták, így már csak ki kellett azokat javítani. 1996-ra a Recognitának tehát világelsõnek számító technológiája volt.
A nagyon céltudatos intenzív technológia fejlesztéssel egyidejûleg egy másfél éves folyamat eredményeként, 1996 végére a cég kiépítette és bevezette, azaz a mindennapi munkában alkalmazta azt a nyugat-európai minõségbiztosítási rendszert, amelyre ugyanez év végén megkapta az ISO 9001 minõségbiztosítási tanúsítványt; megszerzése azonban csak része volt a vállalati minõségpolitikának. A legfontosabb feladat olyan belsõ rendszer megteremtése volt, amelynek segítségével a fejlesztési és más folyamatok professzionális módon kézben tarthatók, azaz tervezhetõk, követhetõk, szükség esetén korrigálhatók. Itt igen fontos szerephez jutott a hazai szoftvervállalatoknál még egyáltalán nem általános folyamat- és termékdokumentálás.
1996-ra kimerültek a vállalat pénzügyi lehetõségei, viszont volt világelsõ technológiánk, és a legigényesebb minõségi követelményeknek megfelelõen szervezett csapat. Megértek tehát a feltételek a stratégiai, azaz hosszú távú, úgynevezett szakmai befektetõ bevonására. Megkezdõdtek a tárgyalások a japán, a német és az amerikai vállalatokkal, és 1996 végére létrejött a megállapodás az amerikai Caere Corporationnel, a Recognita legnagyobb versenytársával a fúzióra: a Recognita 100 százalékban a Caere Corp. európai leányvállalata lett. Ez annak idején az év sikertörténete volt, nemcsak azért, mert egy amerikai vállalat elõször vásárolt meg 100 százalékban magyar szoftvervállalatot, hanem mert a vételár nagyon sokat elárult arról, ahogy a vevõ a Recognitát értékelte. A korábbi ügyletekben a részvények névértékük 100, illetve 138 százalékában cseréltek gazdát, ennél azonban a vevõ a névérték 750(!) százalékát fizette a részvényekért. Mindezt egy olyan pillanatban, amikor a vállalat könyv szerinti értéke, saját vagyona a nullánál is kevesebb (negatív) volt. Sokan aggódtak akkor a Recognitáért, mert a nagyhal megeszi a kishalat hatása érvényesült a Calera felvásárlásakor, azaz a Caere nyomtalanul magába olvasztotta a Recognitánál jóval nagyobb piaci versenytársát is. Az elmúlt három év azonban bizonyította, hogy itt egészen másról volt szó. A Recognita megmaradt magyar vállalatnak, nem kerültek ide amerikai vezetõk. A vállalat saját mûszaki, minõségi és szervezettségi kultúrája erõsödött, az anyavállalattal való kölcsönhatásban nemcsak a magyarok tanultak és gazdagodtak, hanem sok minden átkerült az anyavállalat életébe, valamint beépült termékeibe. Ma már a budapesti projektek nagy részének eredményeként a termékeket a Caere világméretû elosztási csatornáin értékesítjük, lényegesen nagyobb bevételt elérve, mint korábban az önálló Recognitánál. Így a magyar szoftvermérnökök munkája által hozott bevétel ugyanolyan mértékû, mint amerikai kollégáiknál. Azaz elmondhatjuk, hogy itt a magyar munka termelékenysége elérte az amerikai színvonalat, sõt, tekintve, hogy a magyar munka ma még sajnos lényegesen olcsóbb, a mi munkánk termelékenysége magasabb is lett az amerikainál. A Caere-rel kötött házasságot követõ három évben, kihasználva az anyavállalaton keresztüli piaci lehetõségeket, a Recognita ugrásszerûen megnövelte bevételeit, és a hazai iparági átlagnál lényegesen nyereségesebb lett. Így nem csak elvesztett részvénytõkéjét tudta visszatölteni, 1999 végére az úgynevezett saját vagyona a korábbinak a többszöröse lett.
A vállalat teljesítményének elismerése rangos díjakban is megnyilvánul. A cég egymás után háromszor elnyerte az európai informatikai díjat, a The European IT Prize-t. Az elismerésért vívott versenyben az EU országain kívül a kelet- és közép-európai országok, valamint Izrael vállalatai is indulhatnak. 6800 pályázó van évente, és 25 pályamunkát díjaznak. A Recognita az egyetlen vállalat, amely képes volt ezt a díjat háromszor is elnyerni.
Díjazott termékek:
Recognita Form (1996): kitöltött formanyomtatványokat feldolgozó program,
Recognita Reader (1997): speciálisan vakok számára készült OCR-program,
Recognita Plus (1998): általános célú
OCR-program.
Mit hozhat a jövõ?
Az OCR (mint üzlet) legnagyobb gondja, hogy a piac mérete legalábbis ami a bevételi lehetõségeket illeti nem növekszik. Ez a piac évek óta mintegy 100 millió dollár. Hiába nõ a szkennerek száma robbanásszerûen, egyre nagyobb lehetõségeket teremtve az OCR-nek, a szoftver árcsökkenése feléli a darabszámnövekedést, vagyis, a darabszám és az eladási ár szorzata lényegében stagnál. Ez a piaci szereplõk körében egyre erõsödõ koncentrációt eredményez. A régebbiek sorozatos egyesülések árán igyekeznek növekedni, az új szereplõknek pedig egyszerûen nem éri meg belépni egy ennyire beállt piacra.
Az OCR mint technológia fájdalmasan kötõdik a papírhoz, mivel alapvetõen papír alapú dokumentumok feldolgozását célozza. A világ pedig rohamtempóban elektronizálódik. Az e-mailek világában ma már kinek jut eszébe levelet vagy faxot küldeni. Ha csak ezt néznénk, abba is hagyhatnánk minden további erõfeszítést. A helyzet azonban nem ennyire reménytelen. Az archívumokban heverõ hatalmas mennyiségû feldolgozatlan anyag rosszabb minõségû anyagok feldolgozására is alkalmas OCR-technológiát igényel. Változatlanul azt mondjuk, hogy egy OCR legfõbb fokmérõje a minél pontosabb karakter-(szöveg) felismerés. Ezen túl azonban ma már egyre inkább igény a dokumentum szerkezethelyes, alakhelyes visszaadása is (azonos tördelés, azonos fontok stb.).
A másik nagy nyitási terület a formanyomtatványok világa. Mindennapjainkban számtalan formanyomtatvány kitöltésével bíbelõdünk, de ez mind semmi azon gondokhoz képest, amit az ilyen papír alapú nyomtatványok feldolgozása jelent a kibocsátó számára. Ezt kívánják megkönnyíteni azok a képfeldolgozó szoftverek, amelyek a kitöltetlen táblázatokat beszkennelve, azok lay-outját, szerkezetét felismerve segítenek az elektronikus változatot megalkotni, biztosítva egyben az elektronikus kitöltés lehetõségét. A nem elektronikusan kitöltött formanyomtatványok tartalmának felismerésére OCR, ICR, OMR stb. technológiákra támaszkodva fejleszthetünk célmegoldásokat, melyek a nyomtatványok egyes zónáinak tartalmát felismerik, és hozzárendelik a megfelelõ adatbázismezõkhöz.
Új kihívás napjaink robbanásszerûen terjedõ állókép-elõállító(Still Image Capturing) eszköze, a digitális fényképezõgép. Egy ilyen eszközzel akár az utcán lekapott falragasz szövegét is OCR-ezhetjük, amennyiben a program képes például háromdimenziós ferdeségkorrekcióra, valamint a mai digitális fényképezõgépek készítette alacsonyabb felbontású kép megfelelõ feldolgozására. Mindenesetre a jövõ OCR-programjai bizonyára alapozni fognak a digitális fényképezõgépek nyújtotta üzleti lehetõségekre.
Beszélhetnénk még a nyelvi választék
szélesítésérõl mint a piacbõvítés
eszközérõl, ez azonban a Recognita számára
a legújabb változatú program, a Recognita Plus 5.0
kibocsátásával lezárult. A termék ugyanis
ma felismeri a latin betûs karakterkészleteken és a
görögön kívül a cirill nyelvek karaktereit.
Kínai, arab vagy más egzotikus nyelvek irányába
elkalandozni pedig üzletileg megalapozatlan lenne, ugyanis ezeket
a területeket a nyelveket sajátjukként ismerõ
fejlesztõk termékeikkel már kellõ számban
lefedték.
Mit kezdjen az OCR korunk fenoménjával, az internettel?
A Bill Gates-féle (Microsoft) megközelítés
szerint mindenkinek legyen fenn a saját személyi számítógépén
minden elképzelhetõ program, amivel csak egyáltalán
kapcsolatba kerülhet munkájában. Ezen elvnek megfelelõen
egy-két éven belül az OCR igen nagy valószínûséggel
felbukkan valahol a PC-s operációs rendszerek környékén.
A Larry Ellison-féle (Oracle) megközelítés lebutítja
a személyi számítógépeket úgynevezett
Net PC-kre, és az általánosan használt szoftvereket
a publikum számára könnyen hozzáférhetõ
hálózati szerverekre telepíti. Innen lehet szolgáltatásként
lehívni egy-egy programot, amelyek után csak annyit fizetünk,
amilyen mértékben használtuk õket. Eszerint
a megközelítés szerint az OCR-szoftver valahol egy szerveren
ül, mi otthon beszkenneljük a dokumentumot, interneten keresztül
letöltjük a szoftvert, vagy még inkább egyszerûen
csak elküldjük a képet a szervernek, amely azt feldolgozza
és a szövegfájlt visszaküldi. Ilyen ellisonista
megoldások hamarosan elérhetõk lesznek az interneten.
Mindazok tehát, akik csak esetenként akarnak 12 oldalt feldolgozni,
nem kell, hogy saját OCR-szoftverrel rendelkezzenek, a recognitázást
(így nevezik Magyarországon az OCR-ezést) szolgáltatásszerûen
elvégeztethetik.
Irodalom
Kovács E. Marosi I. Benesóczky M. Lánczky J.: Lessons in Character Recognition
Document World, 1996. JulyAugust, p. 3034.
| Természet Világa, | 2000. II. különszám
http://www.kfki.hu/chemonet/TermVil/ http://www.ch.bme.hu/chemonet/TermVil/ |
Vissza a tartalomjegyzékhez